Scaling world understanding for autonomous systems without equivalent cost scaling
2026-06-25
By: Jason Liu, Chao Zhang, Wolf Arnold, Niel Hu
- Advertisement -
The transition from digital AI to physical AI demands a fundamental shift in how machines interact with their environments. While digital AI often operates within neatly structured data or constrained virtual spaces, physical AI must navigate a chaotic, unstructured, and endlessly dynamic real world where the most critical safety events are often rare, long-tail edge cases.
For General Motors, the challenge goes beyond making the right decision in the moment. It also means building the data and validation engine needed to improve autonomous systems safely over time. Mining long-tail scenarios is essential for risk assessment, test creation, validation, and training, since the scenarios that matter most tend to surface only rarely across massive volumes of fleet data.
For example, GM operates a fleet of undreds of test vehicles, which have generated millions of miles of high-quality data captured across multiple sensor and camera streams. On ingestion, this data flows through a pipeline that automatically mines for scenarios of interest, such as near-miss collisions, ambulances on the road, and hard braking events. As we expand our operations, we regularly identify new aspects to mine for, whether a specific form of dangerous debris or a previously unobserved type of road construction equipment.
To improve safely, autonomous systems must convert continuous streams of raw fleet data into a structured, actionable understanding of the driving environment, a monumental perception and interpretation challenge that recent advances in MLLMs are just beginning to address. These models are expanding how machines can understand and reason about the physical world.
While split-second decision-making happens onboard at the edge, the true bottleneck for continuous learning lies in offboard infrastructure that must process vast amounts of fleet data.
- Advertisement -
In this batch-processing environment, a brute-force “MLLM-only” approach quickly hits a wall: compute costs rise rapidly, context windows become overloaded, and subtle but safety-critical events can be missed unless the model is prompted with extreme specificity. This single-layer approach would not be able to power the rapid iteration cycles for new identifications and insights required to empower our physical AI fleet.
To address this scaling bottleneck, we developed EMWU, an offboard, asynchronous pipeline for mining historical fleet data. EMWU acts as a cost-aware multi-tier cascade that separates perception into reusable domain projections and fast candidate retrievals, reserving more expensive deep VLM reasoning for the small fraction of cases that truly require it.
The trap of single-tier MLLM pipelines
- Advertisement -
Modern flagship MLLMs possess impressive spatial and temporal reasoning capabilities, and their context windows are continually expanding. But applying them to millions of high-resolution video clips reveals two fundamental limits:
-
Compute cost escalation: Processing video inputs and generating extended reasoning outputs requires far more compute than text-only prompting. At the scale of millions of clips, applying a flagship MLLM to every clip becomes prohibitively expensive.
-
Long-context reliability degradation: As video inputs grow longer and denser, a single-tier pipeline has less room to incorporate the task-specific context each miner needs within a limited context window. In these settings, models can exhibit “lost in the middle” behavior, underweighting or hallucinating subtle but important temporal interactions.
MLLMs can deliver strong reasoning performance on complex scenes and events, but relying on them as a single-tier pipeline is rarely the most robust or cost-effective way to mine long-tail scenarios from continuous real-world data.
EMWU: A multi-tier systems approach
EMWU operates on a simple systems principle: do the cheapest reusable work first, store the resulting outputs as durable artifacts, and reserve expensive reasoning compute for the limited set of cases that truly warrant it.
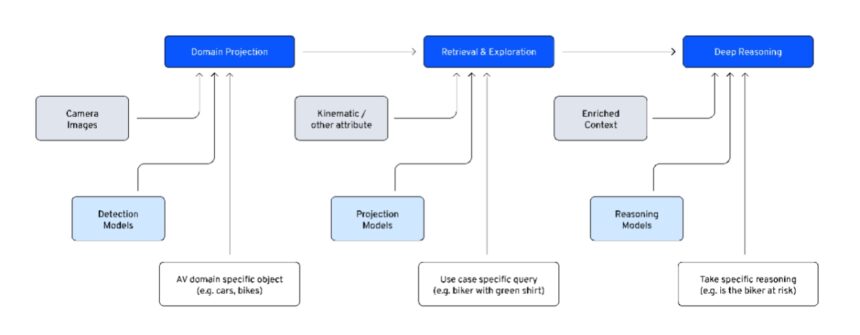
Tier 1: Domain projection (high scale, low unit cost)
The goal of this tier is to convert raw sensor data into reusable, searchable domain artifacts including bounding boxes and embeddings of objects in the autonomous vehicle (AV) domain, such as cars, pedestrians, or traffic lights. We run a detection model (D𝜃 ) with a domain-specific prompt (pcat) to generate bounding boxes (bk) and object tags (ck).
We crop object patches and generate embeddings using an image encoder (𝐸𝜙), alongside low-cost attribute filters.
This is where cost-effective scale is won or lost. Because the Domain Projection tier must be applied across the full corpus of historical fleet data to maximize the data-sourcing pool, scalability and efficiency become central engineering challenges. We engineered a bulk inference pipeline that can produce tens of millions of embeddings per day at a cost of less than $1.00 per 1 million embeddings. We achieved this by optimizing data loading and prefetching, tuning worker parallelism, and maximizing GPU utilization, including near-100% utilization on GPUs.
Tier 2: Retrieval and exploration (fast candidate surfacing)
Instead of feeding raw video to an MLLM, we narrow the search space to a highly relevant candidate set, effectively isolating long-tail needles in a massive data haystack. We then encode a specific user query (Pqry) using a text encoder (T) and run a similarity search over the stored patch embeddings.
For exploratory, interactive searches with relatively low query volumes, we found that maintaining a fully in-memory Hierarchical Navigable Small World (HNSW)-based vector index was not cost-effective. Instead, we relied on Inverted File Index (IVF) approximate nearest neighbor search using k-means clusters, where low-cost storage is a better trade-off than paying to keep the full index in memory.
Tier 3: Deep reasoning (low scale, high precision)
Only when a candidate clip is surfaced do we spend expensive reasoning cycles. The VLM is provided with top K candidate frames, enriched context (A)—such as time window data or multi-camera views—and a task-tailored reasoning prompt (Prsn).
The nuances of spatial and temporal complexity
Why do we need this complex enrichment in Tier 3? Because real-world physics, scene geometry, and agent interactions are inherently ambiguous and complex. High-fidelity understanding hinges on solving two problems that basic embedding searches cannot reliably address.
-
Spatial reasoning challenges:
-
Relational geometry: Critical safety concepts are rarely just object categories; they are relationships, such as relative distance by type of object, intersecting trajectories, and heading alignment.
-
Occlusion and clutter: Real-world scenes feature heavy truncation and occlusion; reasoning must infer plausible states under incomplete evidence without hallucinating.
-
Temporal reasoning challenges:
-
State estimation: Video only provides momentary snapshots, but reasoning requires inferring latent states like intent, attention, and acceleration trends.
-
Causality vs. Correlation: Temporal algorithms must distinguish causal attribution (e.g., did agent A react to agent B?) rather than learning superficial correlations like lighting or traffic density.
Shifting the frontier: Zero-reindexing domain adaptation
A major challenge in adapting foundation models to long-tail, domain-specific data is the cost of recomputing embeddings. If a user needs to retrieve a rare concept that wasn’t well-separated in the original embedding space, traditional methods require full corpus reindexing.
EMWU solves this by introducing automated lightweight model fine-tuning leveraging parameter-efficient adapters like Low-Rank Adaptation (LoRA). We apply these adapters to the text tower of a Contrastive Language-Image Pretraining (CLIP)-style model, keeping the vision encoder frozen. We then train a lightweight linear projection layer (Wc) to align the vision side with the adapted text representations.
At query time, the text embedding is projected as:
q= WcTft(y)
Where ft(y) is the text encoder augmented with LoRA, and Wc is the learned linear projection.
This allows queries to be projected into the existing embedding space for nearest-neighbor search without regenerating a single visual embedding. It requires fewer than 100 labeled examples for long-tail scenarios and avoids expensive database backfills, offering an exceptionally high ROI from a systems perspective.
The result: Balancing the capabilities ceiling
By separating concerns, EMWU manages the trade-offs between cheap retrieval and expensive VLM reasoning.
Engineering for the long tail
Mining rare, long-tail events across millions of hours of fleet video requires treating machine learning as a challenge in both modeling and infrastructure.
EMWU shows that it is possible to preserve the reasoning strength of modern VLMs without accepting unsustainable compute cost. By aggressively filtering through optimized vector retrieval and intelligently projecting text queries into a frozen visual space, the system can surface the exact frames that matter most while reserving expensive reasoning for cases that truly need it.
Equally important is that this architecture creates a path to scale. We are continuing to push the boundaries of what can be pushed into the lowest tiers of the cascade, ensuring that as fleet video volume grows, compute costs scale logarithmically, not linearly.
End-to-end, cost-aware architectures like EMWU are helping build GM’s foundation for physical AI so autonomous systems can learn from real-world driving faster, more efficiently, and with the rigor required to improve safely across an ever-expanding range of conditions.
By: Jason Liu, Chao Zhang, Wolf Arnold, Niel Hu
The transition from digital AI to physical AI demands a fundamental shift in how machines interact with their environments. While digital AI often operates within neatly structured data or constrained virtual spaces, physical AI must navigate a chaotic, unstructured, and endlessly dynamic real world where the most critical safety events are often rare, long-tail edge cases.
For General Motors, the challenge goes beyond making the right decision in the moment. It also means building the data and validation engine needed to improve autonomous systems safely over time. Mining long-tail scenarios is essential for risk assessment, test creation, validation, and training, since the scenarios that matter most tend to surface only rarely across massive volumes of fleet data.
For example, GM operates a fleet of hundreds of test vehicles, which have generated millions of miles of high-quality data captured across multiple sensor and camera streams. On ingestion, this data flows through a pipeline that automatically mines for scenarios of interest, such as near-miss collisions, ambulances on the road, and hard braking events. As we expand our operations, we regularly identify new aspects to mine for, whether a specific form of dangerous debris or a previously unobserved type of road construction equipment.
To improve safely, autonomous systems must convert continuous streams of raw fleet data into a structured, actionable understanding of the driving environment, a monumental perception and interpretation challenge that recent advances in MLLMs are just beginning to address. These models are expanding how machines can understand and reason about the physical world.
While split-second decision-making happens onboard at the edge, the true bottleneck for continuous learning lies in offboard infrastructure that must process vast amounts of fleet data.
In this batch-processing environment, a brute-force “MLLM-only” approach quickly hits a wall: compute costs rise rapidly, context windows become overloaded, and subtle but safety-critical events can be missed unless the model is prompted with extreme specificity. This single-layer approach would not be able to power the rapid iteration cycles for new identifications and insights required to empower our physical AI fleet.
To address this scaling bottleneck, we developed EMWU, an offboard, asynchronous pipeline for mining historical fleet data. EMWU acts as a cost-aware multi-tier cascade that separates perception into reusable domain projections and fast candidate retrievals, reserving more expensive deep VLM reasoning for the small fraction of cases that truly require it.
The trap of single-tier MLLM pipelines
Modern flagship MLLMs possess impressive spatial and temporal reasoning capabilities, and their context windows are continually expanding. But applying them to millions of high-resolution video clips reveals two fundamental limits:
- Compute cost escalation: Processing video inputs and generating extended reasoning outputs requires far more compute than text-only prompting. At the scale of millions of clips, applying a flagship MLLM to every clip becomes prohibitively expensive
- Long-context reliability degradation: As video inputs grow longer and denser, a single-tier pipeline has less room to incorporate the task-specific context each miner needs within a limited context window. In these settings, models can exhibit “lost in the middle” behavior, underweighting or hallucinating subtle but important temporal interactions.
MLLMs can deliver strong reasoning performance on complex scenes and events, but relying on them as a single-tier pipeline is rarely the most robust or cost-effective way to mine long-tail scenarios from continuous real-world data.
EMWU: A multi-tier systems approach
EMWU operates on a simple systems principle: do the cheapest reusable work first, store the resulting outputs as durable artifacts, and reserve expensive reasoning compute for the limited set of cases that truly warrant it.
Tier 1: Domain projection (high scale, low unit cost)
The goal of this tier is to convert raw sensor data into reusable, searchable domain artifacts including bounding boxes and embeddings of objects in the autonomous vehicle (AV) domain, such as cars, pedestrians, or traffic lights. We run a detection model (D𝜃 ) with a domain-specific prompt (pcat) to generate bounding boxes (bk) and object tags (ck).
We crop object patches and generate embeddings using an image encoder (𝐸𝜙), alongside low-cost attribute filters.
This is where cost-effective scale is won or lost. Because the Domain Projection tier must be applied across the full corpus of historical fleet data to maximize the data-sourcing pool, scalability and efficiency become central engineering challenges. We engineered a bulk inference pipeline that can produce tens of millions of embeddings per day at a cost of less than $1.00 per 1 million embeddings. We achieved this by optimizing data loading and prefetching, tuning worker parallelism, and maximizing GPU utilization, including near-100% utilization on GPUs.
Tier 2: Retrieval and exploration (fast candidate surfacing)
Instead of feeding raw video to an MLLM, we narrow the search space to a highly relevant candidate set, effectively isolating long-tail needles in a massive data haystack. We then encode a specific user query (Pqry) using a text encoder (T) and run a similarity search over the stored patch embeddings.
For exploratory, interactive searches with relatively low query volumes, we found that maintaining a fully in-memory Hierarchical Navigable Small World (HNSW)-based vector index was not cost-effective. Instead, we relied on Inverted File Index (IVF) approximate nearest neighbor search using k-means clusters, where low-cost storage is a better trade-off than paying to keep the full index in memory.
Tier 3: Deep reasoning (low scale, high precision)
Only when a candidate clip is surfaced do we spend expensive reasoning cycles. The VLM is provided with top K candidate frames, enriched context (A)—such as time window data or multi-camera views—and a task-tailored reasoning prompt (Prsn).
The nuances of spatial and temporal complexity
Why do we need this complex enrichment in Tier 3? Because real-world physics, scene geometry, and agent interactions are inherently ambiguous and complex. High-fidelity understanding hinges on solving two problems that basic embedding searches cannot reliably address.
-
Spatial reasoning challenges:
-
Relational geometry: Critical safety concepts are rarely just object categories; they are relationships, such as relative distance by type of object, intersecting trajectories, and heading alignment.
-
Occlusion and clutter: Real-world scenes feature heavy truncation and occlusion; reasoning must infer plausible states under incomplete evidence without hallucinating.
-
-
Temporal reasoning challenges:
-
State estimation: Video only provides momentary snapshots, but reasoning requires inferring latent states like intent, attention, and acceleration trends.
-
Causality vs. Correlation: Temporal algorithms must distinguish causal attribution (e.g., did agent A react to agent B?) rather than learning superficial correlations like lighting or traffic density.
-
Shifting the frontier: Zero-reindexing domain adaptation
A major challenge in adapting foundation models to long-tail, domain-specific data is the cost of recomputing embeddings. If a user needs to retrieve a rare concept that wasn’t well-separated in the original embedding space, traditional methods require full corpus reindexing.
EMWU solves this by introducing automated lightweight model fine-tuning leveraging parameter-efficient adapters like Low-Rank Adaptation (LoRA). We apply these adapters to the text tower of a Contrastive Language-Image Pretraining (CLIP)-style model, keeping the vision encoder frozen. We then train a lightweight linear projection layer (Wc) to align the vision side with the adapted text representations.
At query time, the text embedding is projected as:
q= WcTft(y)
Where ft(y) is the text encoder augmented with LoRA, and Wc is the learned linear projection.
This allows queries to be projected into the existing embedding space for nearest-neighbor search without regenerating a single visual embedding. It requires fewer than 100 labeled examples for long-tail scenarios and avoids expensive database backfills, offering an exceptionally high ROI from a systems perspective.
The result: Balancing the capabilities ceiling
By separating concerns, EMWU manages the trade-offs between cheap retrieval and expensive VLM reasoning.
Engineering for the long tail
Mining rare, long-tail events across millions of hours of fleet video requires treating machine learning as a challenge in both modeling and infrastructure.
EMWU shows that it is possible to preserve the reasoning strength of modern VLMs without accepting unsustainable compute cost. By aggressively filtering through optimized vector retrieval and intelligently projecting text queries into a frozen visual space, the system can surface the exact frames that matter most while reserving expensive reasoning for cases that truly need it.
Equally important is that this architecture creates a path to scale. We are continuing to push the boundaries of what can be pushed into the lowest tiers of the cascade, ensuring that as fleet video volume grows, compute costs scale logarithmically, not linearly.
End-to-end, cost-aware architectures like EMWU are helping build GM’s foundation for physical AI so autonomous systems can learn from real-world driving faster, more efficiently, and with the rigor required to improve safely across an ever-expanding range of conditions.
Scaling world understanding for autonomous systems without equivalent cost scaling
2026-06-25 14:00:00
media.gm.com
https://media.gm.com/content/media/us/en/gm/home.detail.html/content/Pages/news/us/en/engineering/2026/jun/0625-scaling-autonomous-systems.html
#Scaling #world #understanding #autonomous #systems #equivalent #cost #scaling





